- Published on
Meet Kafka
- Authors

- Name
- EL-FAHIM Maymoun
- @Amalou88188197
Introduction
Every entreprise is powered by data. We take information in, analyse it, manipulate it, and create more as output. Every application creates data, wether it is log messages, metrics, user activity, outgoing messages, or somethings else. Every byte of data has a stort to tell, something of importance that will inform the next things to be done. In order to know what that is, we need to get the data from where it is created to where it can be analyzed. We see yhis every day on websites like Amazon, where our clicks on items of interest to us are tuned into recommendations that are shown to us a little later.
- Publish/Subscribe Messaging
- Messages and Batches
- Schemas
- Topics and Partitions
- Producers and Consumers
- Brokers and Clusters
- Multiple Clusters
- Conclusion
Publish/Subscribe Messaging
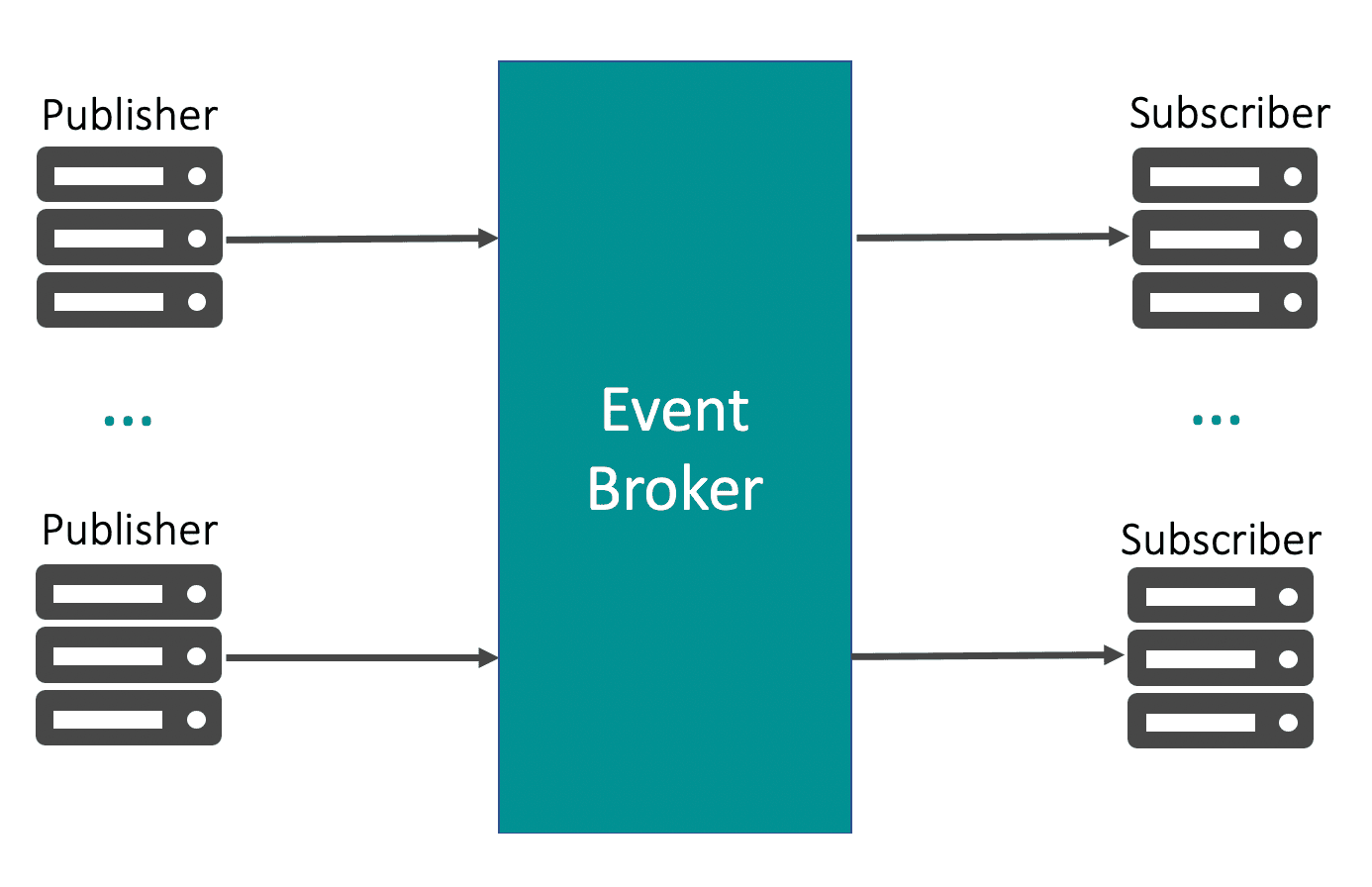
Publish/subscribe (pub/sub) messaging is a pattern that is characterized by the sender (publisher) of a piece of data (message) not specifically directing it to a receiver. Instead, the publisher classifies the message somehow, and that receiver (subscribe) subscribe to receive certain classes of messages. Bpu/Sub system often have a broker, a central point where messages are published, to facilitate this pattern.
Apache Kafka was developed as a publish/subscribe messaging system designed to solve business grows problems.kafka facilitate having a single centralized system that allows for pblishing generic types of data.
Messages and Batches
The unit of data within Kafka is called a message, similar to a row or record in database environement.A message is simply an array of bytes as a Kafka is concerned, a message can have an optional piece of metadata, witch is referred to as a key. For effeciency, messages are written into Kafka in batches. A batch is just a collection of messages, all of witchare being produced to the same topic and partition.Of course, these is a trade-off between latency and throughput: the larger the batches, the more messages that can be handled per unit of time, but the longer it takes an individual message to propagate.
Schemas
While messaging are opaque byte arrays to Kafka itself, it is recommended that additionnal structure, or schema, be imposed on the message content so that it can be easily understood. There are many options available for message schema, depending in application individual needs. Simplistic systems, such as JSON and XML are easy to use and human readable.However, they lack features such as robust type handling and compatibility between schema versions. Many Kafka developers favor the use of Apache Avro which is a serialization frameworkoriginally developed for Hadoop.
Topics and Partitions
Messages in Kafka are categorized into topics. The closest analogies for a topic are a database table. Topics are additionally broken down into a number of partitionss.Note that as a topic typically has multiple partitions, there is no guarantee of message ordering across the entire topic, just within a single partition. Partitions are also the way that Kafka provides redundancy ans scalability.Each partition can be hosted on a different server, which means that a single topic can be scaled horizontally.
Producers and Consumers
Producers, also known as publishers or writers in other publish/subscribe systems, generate new messages. Typically, these messages are assigned to specific topics. By default, producers distribute messages evenly across all partitions of a topic without concern for individual partitioning. However, in certain scenarios, producers may target specific partitions for message delivery. This is achieved using a message key and a partitioner, which generates a hash of the key to map it to a particular partition. This ensures that messages with the same key are consistently written to the same partition. Alternatively, producers can employ custom partitioners that adhere to specific business rules for partition mapping.
Consumers, referred to as subscribers or readers in other systems, retrieve messages. They subscribe to one or more topics and consume messages in the order they were produced. To keep track of consumed messages, consumers maintain offsets—integer values that Kafka appends to each message upon production. Each message within a partition possesses a unique offset. By storing the offset of the last consumed message for each partition, either in Zookeeper or within Kafka itself, consumers can halt and resume consumption without losing their progress.
Brokers and Clusters
A single Kafka server is called a broker. The broker receives messages from producers, assigns offsets to them, and commits the messages to storage on disk. It also services consumers, responding to fetch requests for partitions and responding with the messages that have been committed to disk. Kafka brokers are designed to operate as part of a cluster. Within a cluster of brokers,one broker will also function as the cluster controller (elected automatically from the live members of the cluster).
Multiple Clusters
As Kafka deployments grow, it is often advantageous to have multiple clusters. There are several reasons why this can be useful: • Segregation of types of data • Isolation for security requirements • Multiple datacenters (disaster recovery)
Conclusion
I hope you enjoy the new features and improvements in V2. If you have any feedback or suggestions, feel free to open an issue or reach out to me on Twitter.